
Estimating the Normalized Pairwise Variability Index
The Pairwise Variability Index, first developed by Francis Nolan (see [1]), has found wide use in the study of (some notion of) rhythm in speech, e.g. in [2]. My concern here is with the normalized PVI index, which is calculated for a set of m intervals as follows:
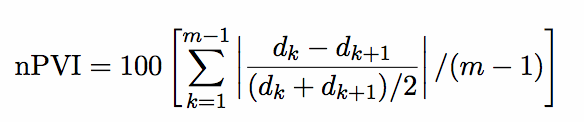
I will assume a situation in which you wish to calculate the nPVI for a series of syllable onsets in a single sentence, Assume you start with a soundfile containing your sentence. You could label syllable onsets by hand. That would be hard work, and would also require you to choose some arbitrary point as representing the onset of the syllable. An easier and more consistent approach is to use my beat extraction algorithm to obtain a set of automatically calculated estimates of the P-center for each syllable. Here are instructions for doing just that. If you follow those instructions, you will have something like this:
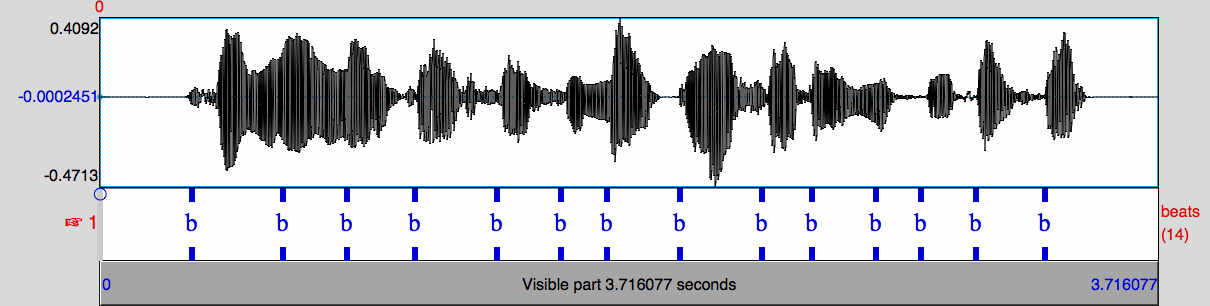
Of course, you will have to check the beats by hand, to ensure that you have one beat for each syllable onset, and no other beats. You may need to alter the threshold, and/or the filter parameters used in the beat extraction process.
Download this Perl script: getNPvi.pl. Make sure it is executable on your computer. Run it, providing the beat file generated above, thus:
getNPvi.pl someSoundFile.beats
The program should output the nPVI, which is a number between p and 100. have fun.
References
- Nolan, F. and Asu, E. (2009). The pairwise variability index and coexisting rhythms in language. Phonetica, 66(1-2):64–77.
- Grabe, E. and Low, E. (2002). Durational variability in speech and the rhythm class hypothesis. Laboratory Phonology 7.